Data Preprocessing | Các phương pháp tiền xử lí dữ liệu (Đang cập nhật)


Data Cleaning
Dữ liệu là trọng tâm của mọi hoạt động liên quan đến phân tích và đưa ra quyết định trong thế giới số ngày nay. Tuy nhiên, trước khi có thể thực hiện bất kỳ phân tích nào, việc làm sạch dữ liệu là bước quan trọng và không thể bỏ qua. Đây được gọi là Data Cleaning (làm sạch dữ liệu), một quy trình tất yếu để đảm bảo rằng dữ liệu mà bạn sử dụng là đáng tin cậy, phù hợp và có thể dùng cho việc phân tích hoặc các yêu cầu nghiệp vụ nào đó.
Data Cleaning bao gồm một loạt các bước và kỹ thuật, bao gồm:
1. Loại bỏ dữ liệu trùng lặp:
Điều này đảm bảo rằng mỗi mục dữ liệu chỉ xuất hiện một lần trong tập dữ liệu của bạn, tránh sự thiên vị, lệch trong kết quả phân tích.
2. Xử lý giá trị bị thiếu (Handling missing values):
Dữ liệu thường có giá trị bị thiếu hoặc không xác định, và việc xử lý chúng là bước quan trọng trong Data Cleaning. Có thể thay thế giá trị thiếu bằng giá trị trung bình, giá trị phổ biến nhất hoặc dự đoán từ các phương pháp học máy. Một số phương pháp có thể tham khảo như:
- Điền giá trị thiếu bằng cách thủ công:
Tự điền từng giá trị thiếu một cách thủ công là công việc mất thời gian và công sức, do đó chỉ thực hiện khi số lượng giá trị thiếu ít.- Sử dụng một hằng số chung để thay thế giá trị thiếu:
Trong phương pháp này, giá trị thiếu được thay thế bằng một nhãn toàn cục như 'Unknown', 0, hoặc -∞. Mặc dù đây là một trong những cách tiếp cận dễ dàng nhất để xử lý các giá trị thiếu, nhưng nên tránh khi chương trình khai thác dữ liệu xuất hiện một mẫu do sự lặp lại của các nhãn toàn cục như 'Unknown'.
Ví dụ: Trong lĩnh vực quảng cáo, User-agent đóng vai trò quan trọng để phân loại người dùng dựa trên thiết bị sử dụng. Tuy nhiên, đôi khi thông tin này không thể thu thập được do nhiều lý do, như sự xuất hiện của các thiết bị mới hoặc việc người dùng sử dụng VPN. Trong trường hợp này, việc xử lý dữ liệu thiếu bằng cách thay thế bằng giá trị "Unknown" có thể làm cho quá trình phân tích trở nên phức tạp hơn.
- Sử dụng giá trị trung bình của thuộc tính để điền vào giá trị thiếu:
Điền vào các giá trị thiếu cho mỗi thuộc tính bằng giá trị trung bình của các giá trị dữ liệu khác của cùng một thuộc tính. Đây là một cách tốt hơn để xử lý các giá trị thiếu trong một tập dữ liệu.
Ví dụ, giả sử chúng ta có một tập dữ liệu gồm các thông tin về chiều cao của các học sinh, trong đó một số học sinh không có thông tin chiều cao. Chúng ta có thể sử dụng giá trị trung bình của chiều cao của các học sinh khác để điền vào các giá trị thiếu này. Tuy nhiên việc sử dụng giá trị trung bình có thể gây ra sai số nhất định, làm ảnh hưởng đến kết quả cuối cùng của việc phân tích. So sánh bối cảnh khi 5 học sinh có chiều cao 1m7 và 1 học sinh có giá trị 1m5 với bối cảnh 5 học sinh có chiều cao 1m5 và 5 học sinh có chiều cao 1m7, giá trị trung bình sẽ khá khác biệt.
Để giải quyết vấn đề này, một số phương pháp như áp dụng độ lệch chuẩn khi xử lí cũng là một cách, tuy nhiên đối với tập dữ liệu lớn với các khoảng gía trị chênh lệch cũng không mang lại kết quả tốt.

Ảnh. Bài toán thu thập dữ liệu nhiệt độ từ cảm biến trong tủ đông của siêu thị
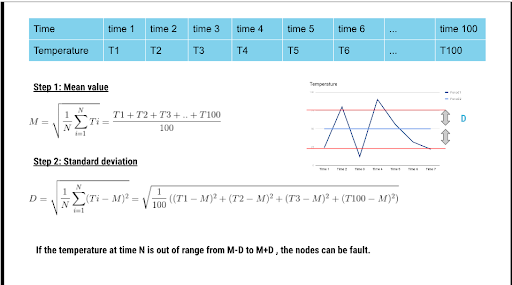
Ảnh. Áp dụng công thức độ lệch chuẩn để làm giảm sai số và bổ sung các giá trị thiếu trong quá trình thu thập tại một thời điểm trong ngày.
- Sử dụng một giá trị khác có xác suất cao để điền vào giá trị thiếu:
Một phương pháp hiệu quả khác là điền vào các giá trị thiếu bằng các giá trị được xác định bởi các công cụ như Hình thức Bayesian hoặc Rừng quyết định hoặc các công cụ dựa trên suy diễn khác. Đây là một trong những phương pháp tốt nhất, vì nó sử dụng hầu hết thông tin đã có để dự đoán các giá trị thiếu, mặc dù nó không bị thiên vị như các phương pháp trước đó. Điều khó khăn duy nhất của phương pháp này là sự phức tạp trong việc thực hiện phân tích.
TODO:
Bayesian Formalism or Decision Tree Induction or other inference-based tools
- Bỏ qua bộ dữ liệu:
Nếu bộ dữ liệu chứa nhiều hơn một giá trị thiếu và tất cả các phương pháp khác không áp dụng, thì chiến lược tốt nhất để xử lý các giá trị thiếu là bỏ qua toàn bộ bộ dữ liệu. Điều này thường được sử dụng nếu nhãn lớp bị mất hoặc bộ dữ liệu chứa các giá trị thiếu cho hầu hết các thuộc tính. Phương pháp này không nên được sử dụng nếu tỷ lệ giá trị thiếu cho mỗi thuộc tính thay đổi đáng kể.
3. Kiểm tra tính nhất quán và độ chính xác:
Đôi khi dữ liệu có thể không nhất quán hoặc chứa các giá trị không hợp lệ. Việc kiểm tra và sửa các lỗi này là cần thiết để đảm bảo tính nhất quán và độ chính xác của dữ liệu.
4. Chuẩn hóa dữ liệu:
Khi làm việc với dữ liệu từ nhiều nguồn khác nhau, đôi khi cần phải chuẩn hóa dữ liệu để đảm bảo rằng chúng có cùng định dạng và đơn vị đo.
5. Loại bỏ nhiễu (Handling noisy data):
Dữ liệu có thể bị nhiễu bởi các giá trị bất thường hoặc không hợp lý. Việc loại bỏ nhiễu giúp cải thiện chất lượng dữ liệu và kết quả của phân tích.
Binning methods
Phương pháp "binning" là một kỹ thuật quan trọng trong xử lý dữ liệu và phân tích thống kê, được sử dụng để chia dữ liệu thành các nhóm (các "bin") dựa trên giá trị của một biến liên tục. Các phương pháp binning cung cấp cách tiếp cận đơn giản nhưng mạnh mẽ để tóm tắt dữ liệu và phân loại nó thành các nhóm dễ hiểu và quản lý. Dưới đây là một số phương pháp binning phổ biến:
a. Equal Internal Binning (Phân chia đều về độ rộng):
Trong phương pháp này, miền giá trị của biến được chia thành các khoảng có cùng độ rộng. Ví dụ, nếu biến có giá trị từ 0 đến 100 và chúng ta muốn chia thành 5 nhóm, mỗi nhóm sẽ có độ rộng là 20. Phương pháp này dễ thực hiện nhưng có thể dẫn đến sự không chính xác nếu phân phối của dữ liệu không đồng đều.
b. Equal Frequency Binning (Phân chia đều về tần số):
Trong phương pháp này, dữ liệu được chia thành các nhóm có số lượng quan sát gần như bằng nhau. Thay vì chia theo độ rộng, chúng ta chia dựa trên tần suất của dữ liệu. Điều này giúp đảm bảo mỗi nhóm có số lượng quan sát gần như như nhau, nhưng có thể dẫn đến sự không đồng đều về phân phối giữa các nhóm.|c. Custom Binning (Phân chia tùy chỉnh):
Trong phương pháp này, người dùng xác định các ranh giới của các nhóm dựa trên kiến thức chuyên môn hoặc mục tiêu cụ thể của mình. Ví dụ, khi phân loại tuổi thành các nhóm như "trẻ em", "thanh thiếu niên", "người trưởng thành", "người già", ranh giới có thể được định nghĩa dựa trên quan điểm của người phân tích.
- Entropy-based Binning (Phân chia dựa trên entropy): Phương pháp này chia dữ liệu thành các nhóm sao cho mỗi nhóm có tính đồng nhất cao, được đo bằng entropy hoặc một chỉ số tương tự. Mục tiêu là giảm thiểu độ lệch thông tin giữa các nhóm và tạo ra các nhóm có tính đồng nhất cao.
- Phương pháp binning phù hợp sẽ phụ thuộc vào bản chất của dữ liệu cũng như mục tiêu phân tích của bạn. Một cách tiếp cận linh hoạt là kết hợp các phương pháp khác nhau để tạo ra một phân chia dữ liệu có ý nghĩa và hữu ích cho bài toán cụ thể của bạn.
- Clustering or outlier analysis
- Regression
- Combined computer and human inspection
6. Kiểm tra và xử lý các lỗi nhập liệu:
Lỗi nhập liệu có thể xuất hiện do sai sót của con người hoặc quá trình tự động nhập liệu. Việc kiểm tra và sửa các lỗi này là quan trọng để đảm bảo tính chính xác của dữ liệu.
Tóm lại, Data Cleaning không chỉ là bước tiền đề cho mọi phân tích dữ liệu mà còn là bước quan trọng để đảm bảo tính chính xác và đáng tin cậy của kết quả cuối cùng. Quy trình này đòi hỏi sự tỉ mỉ, kiên nhẫn và kiến thức vững chắc về dữ liệu và các kỹ thuật xử lý dữ liệu.